 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Safety Benchmarking: A Multi-agent Pipeline for LVLMs
Jan 27, 2026Large vision-language models (LVLMs) exhibit remarkable capabilities in cross-modal tasks but face significant safety challenges, which undermine their reliability in real-world applications. Efforts have been made to build LVLM safety evaluation benchmarks to uncover their vulnerability. However, existing benchmarks are hindered by their labor-intensive construction process, static complexity, and limited discriminative power. Thus, they may fail to keep pace with rapidly evolving models and emerging risks. To address these limitations, we propose VLSafetyBencher, the first automated system for LVLM safety benchmarking. VLSafetyBencher introduces four collaborative agents: Data Preprocessing, Generation, Augmentation, and Selection agents to construct and select high-quality samples. Experiments validates that VLSafetyBencher can construct high-quality safety benchmarks within one week at a minimal cost. The generated benchmark effectively distinguish safety, with a safety rate disparity of 70% between the most and least safe models.
QualiRAG: Retrieval-Augmented Generation for Visual Quality Understanding
Jan 26, 2026Visual quality assessment (VQA) is increasingly shifting from scalar score prediction toward interpretable quality understanding -- a paradigm that demands \textit{fine-grained spatiotemporal perception} and \textit{auxiliary contextual information}. Current approaches rely on supervised fine-tuning or reinforcement learning on curated instruction datasets, which involve labor-intensive annotation and are prone to dataset-specific biases. To address these challenges, we propose \textbf{QualiRAG}, a \textit{training-free} \textbf{R}etrieval-\textbf{A}ugmented \textbf{G}eneration \textbf{(RAG)} framework that systematically leverages the latent perceptual knowledge of large multimodal models (LMMs) for visual quality perception. Unlike conventional RAG that retrieves from static corpora, QualiRAG dynamically generates auxiliary knowledge by decomposing questions into structured requests and constructing four complementary knowledge sources: \textit{visual metadata}, \textit{subject localization}, \textit{global quality summaries}, and \textit{local quality descriptions}, followed by relevance-aware retrieval for evidence-grounded reasoning. Extensive experiments show that QualiRAG achieves substantial improvements over open-source general-purpose LMMs and VQA-finetuned LMMs on visual quality understanding tasks, and delivers competitive performance on visual quality comparison tasks, demonstrating robust quality assessment capabilities without any task-specific training. The code will be publicly available at https://github.com/clh124/QualiRAG.
Embodied Image Compression
Dec 12, 2025



Image Compression for Machines (ICM) has emerged as a pivotal research direction in the field of visual data compression. However, with the rapid evolution of machine intelligence, the target of compression has shifted from task-specific virtual models to Embodied agents operating in real-world environments. To address the communication constraints of Embodied AI in multi-agent systems and ensure real-time task execution, this paper introduces, for the first time, the scientific problem of Embodied Image Compression. We establish a standardized benchmark, EmbodiedComp, to facilitate systematic evaluation under ultra-low bitrate conditions in a closed-loop setting. Through extensive empirical studies in both simulated and real-world settings, we demonstrate that existing Vision-Language-Action models (VLAs) fail to reliably perform even simple manipulation tasks when compressed below the Embodied bitrate threshold. We anticipate that EmbodiedComp will catalyze the development of domain-specific compression tailored for Embodied agents , thereby accelerating the Embodied AI deployment in the Real-world.
One Battle After Another: Probing LLMs' Limits on Multi-Turn Instruction Following with a Benchmark Evolving Framework
Nov 05, 2025Understanding how well large language models can follow users' instructions throughout a dialogue spanning multiple topics is of great importance for data-intensive conversational applications. Existing benchmarks are often limited to a fixed number of turns, making them susceptible to saturation and failing to account for the user's interactive experience. In this work, we propose an extensible framework for assessing multi-turn instruction-following ability. At its core, our framework decouples linguistic surface forms from user intent simulation through a three-layer mechanism that tracks constraints, instructions, and topics. This framework mimics User-LLM interaction by enabling the dynamic construction of benchmarks with state changes and tracebacks, terminating a conversation only when the model exhausts a simulated user's patience. We define a suite of metrics capturing the quality of the interaction process. Using this framework, we construct EvolIF, an evolving instruction-following benchmark incorporating nine distinct constraint types. Our results indicate that GPT-5 exhibits superior instruction-following performance. It sustains an average of 18.54 conversational turns and demonstrates 70.31% robustness, outperforming Gemini-2.5-Pro by a significant margin of 11.41%, while other models lag far behind. All of the data and code will be made publicly available online.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
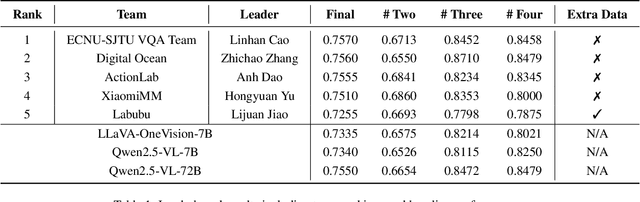
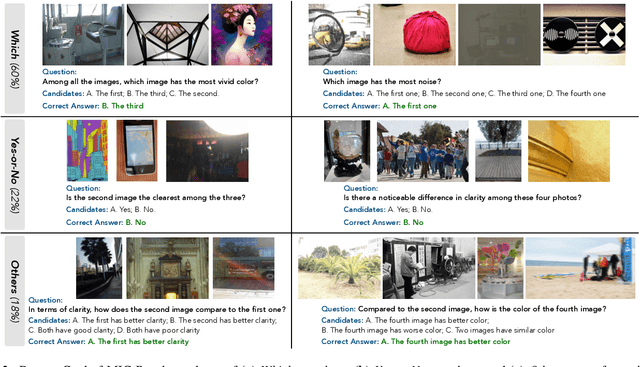
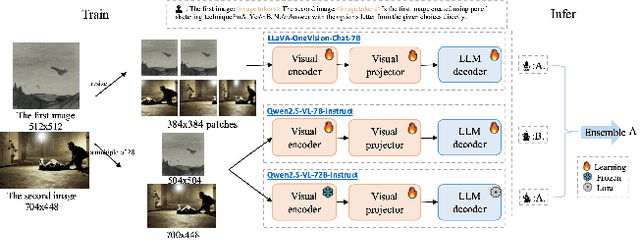
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
SDEval: Safety Dynamic Evaluation for Multimodal Large Language Models
Aug 08, 2025



In the rapidly evolving landscape of Multimodal Large Language Models (MLLMs), the safety concerns of their outputs have earned significant attention. Although numerous datasets have been proposed, they may become outdated with MLLM advancements and are susceptible to data contamination issues. To address these problems, we propose \textbf{SDEval}, the \textit{first} safety dynamic evaluation framework to controllably adjust the distribution and complexity of safety benchmarks. Specifically, SDEval mainly adopts three dynamic strategies: text, image, and text-image dynamics to generate new samples from original benchmarks. We first explore the individual effects of text and image dynamics on model safety. Then, we find that injecting text dynamics into images can further impact safety, and conversely, injecting image dynamics into text also leads to safety risks. SDEval is general enough to be applied to various existing safety and even capability benchmarks. Experiments across safety benchmarks, MLLMGuard and VLSBench, and capability benchmarks, MMBench and MMVet, show that SDEval significantly influences safety evaluation, mitigates data contamination, and exposes safety limitations of MLLMs. Code is available at https://github.com/hq-King/SDEval
Perceptual Quality Assessment for Embodied AI
May 22, 2025



Embodied AI has developed rapidly in recent years, but it is still mainly deployed in laboratories, with various distortions in the Real-world limiting its application. Traditionally, Image Quality Assessment (IQA) methods are applied to predict human preferences for distorted images; however, there is no IQA method to assess the usability of an image in embodied tasks, namely, the perceptual quality for robots. To provide accurate and reliable quality indicators for future embodied scenarios, we first propose the topic: IQA for Embodied AI. Specifically, we (1) based on the Mertonian system and meta-cognitive theory, constructed a perception-cognition-decision-execution pipeline and defined a comprehensive subjective score collection process; (2) established the Embodied-IQA database, containing over 36k reference/distorted image pairs, with more than 5m fine-grained annotations provided by Vision Language Models/Vision Language Action-models/Real-world robots; (3) trained and validated the performance of mainstream IQA methods on Embodied-IQA, demonstrating the need to develop more accurate quality indicators for Embodied AI. We sincerely hope that through evaluation, we can promote the application of Embodied AI under complex distortions in the Real-world. Project page: https://github.com/lcysyzxdxc/EmbodiedIQA
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Mar 27, 2025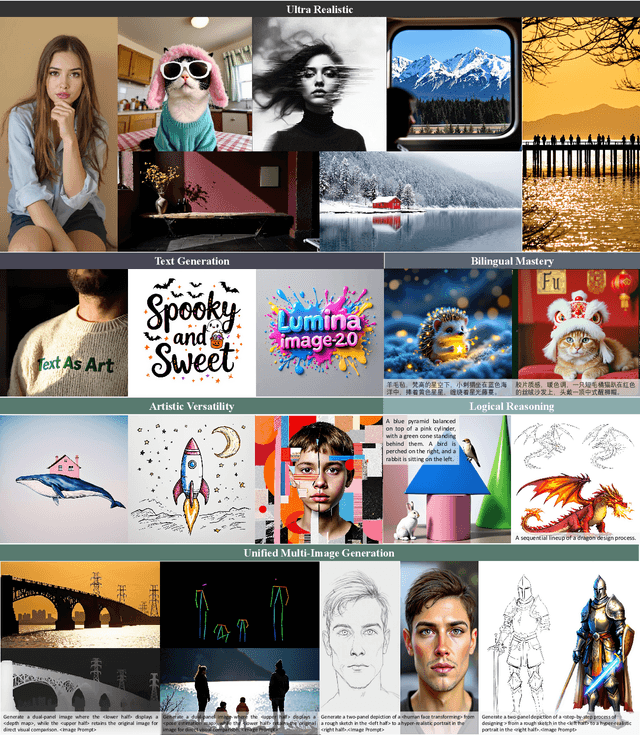
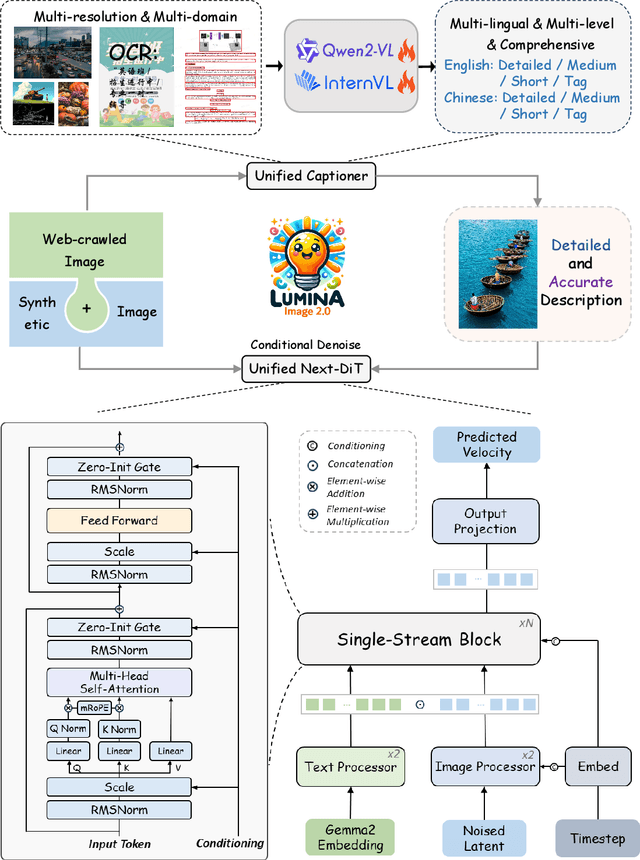

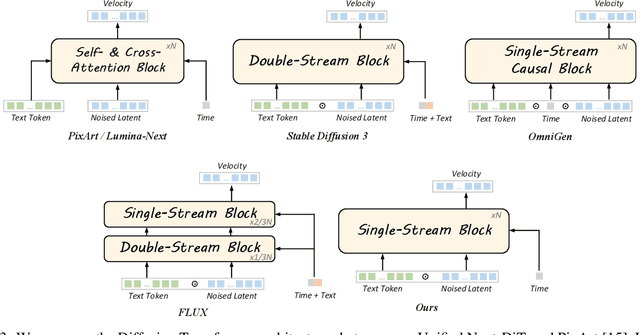
We introduce Lumina-Image 2.0, an advanced text-to-image generation framework that achieves significant progress compared to previous work, Lumina-Next. Lumina-Image 2.0 is built upon two key principles: (1) Unification - it adopts a unified architecture (Unified Next-DiT) that treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion. Besides, since high-quality captioners can provide semantically well-aligned text-image training pairs, we introduce a unified captioning system, Unified Captioner (UniCap), specifically designed for T2I generation tasks. UniCap excels at generating comprehensive and accurate captions, accelerating convergence and enhancing prompt adherence. (2) Efficiency - to improve the efficiency of our proposed model, we develop multi-stage progressive training strategies and introduce inference acceleration techniques without compromising image quality. Extensive evaluations on academic benchmarks and public text-to-image arenas show that Lumina-Image 2.0 delivers strong performances even with only 2.6B parameters, highlighting its scalability and design efficiency. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-Image-2.0.
SAM2Point: Segment Any 3D as Videos in Zero-shot and Promptable Manners
Aug 29, 2024



We introduce SAM2Point, a preliminary exploration adapting Segment Anything Model 2 (SAM 2) for zero-shot and promptable 3D segmentation. SAM2Point interprets any 3D data as a series of multi-directional videos, and leverages SAM 2 for 3D-space segmentation, without further training or 2D-3D projection. Our framework supports various prompt types, including 3D points, boxes, and masks, and can generalize across diverse scenarios, such as 3D objects, indoor scenes, outdoor environments, and raw sparse LiDAR. Demonstrations on multiple 3D datasets, e.g., Objaverse, S3DIS, ScanNet, Semantic3D, and KITTI, highlight the robust generalization capabilities of SAM2Point. To our best knowledge, we present the most faithful implementation of SAM in 3D, which may serve as a starting point for future research in promptable 3D segmentation. Online Demo: https://huggingface.co/spaces/ZiyuG/SAM2Point . Code: https://github.com/ZiyuGuo99/SAM2Point .
No Time to Train: Empowering Non-Parametric Networks for Few-shot 3D Scene Segmentation
Apr 05, 2024



To reduce the reliance on large-scale datasets, recent works in 3D segmentation resort to few-shot learning. Current 3D few-shot segmentation methods first pre-train models on 'seen' classes, and then evaluate their generalization performance on 'unseen' classes. However, the prior pre-training stage not only introduces excessive time overhead but also incurs a significant domain gap on 'unseen' classes. To tackle these issues, we propose a Non-parametric Network for few-shot 3D Segmentation, Seg-NN, and its Parametric variant, Seg-PN. Without training, Seg-NN extracts dense representations by hand-crafted filters and achieves comparable performance to existing parametric models. Due to the elimination of pre-training, Seg-NN can alleviate the domain gap issue and save a substantial amount of time. Based on Seg-NN, Seg-PN only requires training a lightweight QUEry-Support Transferring (QUEST) module, which enhances the interaction between the support set and query set. Experiments suggest that Seg-PN outperforms previous state-of-the-art method by +4.19% and +7.71% mIoU on S3DIS and ScanNet datasets respectively, while reducing training time by -90%, indicating its effectiveness and efficiency.